In the recent months I’be been developing a Search API – using Amazon Elasticsearch Service in the background.
Elasticsearch is a well known, widely used, and well documented product. It was very simple to get it run. However, we encountered some interesting behaviour, which determined us to dig deeper.
My first posts will cover two problems we had to face: poor result relevance and inconsistent results. Our findings and solutions can be useful for any of you interested in Elasticsearch, because the topics don’t focus on the Amazon ES implementation.
 And now, let’s get into the details.
And now, let’s get into the details.
Poor result relevance
After the first iteration of our implementation (we mostly went on with the basic ES cluster settings and default mappings) we realised that our free text search results are not relevant enough.
When searching for “London” for example, we would have received a lot of organisations with “London” in their names, but the location “London” was not in the first 50 results.
How could this happen?
A bit of theory
Elasticsearch calculates relevance score for free text search based on some field statistics, such as: term frequency, inverse document frequency and field-length norm.
- Term frequency describes how frequently a term appears inside a text: the more often, the more relevant the document is.
- Inverse document frequency balances the above metric, following the idea that the more often a term appears in all the documents, the less relevant is for our specific search. This means, that if we have a term which is present in all the documents, it’s most probably a general one, which wouldn’t have an added value for our search, so it’s less relevant in scoring.
- Field length norm attributes a higher score for matches inside a short field, than for matches found in a longer one.
In order to better understand the impact of the above scoring mechanism, we must understand how Elasticsearch splits its content between shards and replicas.
- An element of the content inside an index is called a document.
- Documents are split over multiple nodes (physical units).
- A shard is a collection of documents, that makes the distribution of the data possible all over the nodes.
- A replica is a copy of a primary shard.
- On a single node there can be multiple shards (both primaries and replicas).
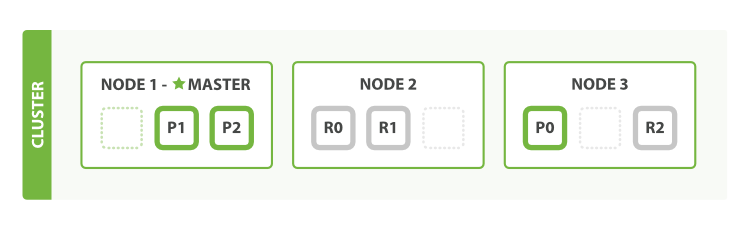
And now, let’s get back to our metrics. The inverse document frequency is calculated over the documents inside a shard – and not over all the data inside an index. With longer text fields, and a big volume of total documents: the results should be balanced.
How did this hit us?
The discrepancy for the “London” case was caused exactly by the above mentioned shard/document distribution (check poor document relevance). It happened that the location term “London” got into a shard, where there were numerous other documents with “London” in their names. In the other shards, there were only a few documents with “London”, so they ended up with higher scores, and came up as being more relevant in the final result set.
How did we fix it?
It is very important not to have more shards than required for an index. Some advice about shard optimisation is described in this article.
The main ideas here are:
- max shard size should be between 30-32 GB
- total number of shards has to be between 1.5-3 x no. of nodes
- in our case we have 5 shards/index for 64 GB – a bit high, but should do it
We realized that we cannot fully fix the accuracy by fixing the shard configs, so we decided to double the score for exact matches against the partial ones, using Query boosting.
***
This was only one example from my exciting Elasticsearch journey. The Amazon experience was also quite pleasant. Maybe I will add a post about that some day.
